

Sai come funziona Google? Beh, nel dettaglio nemmeno io. Anzi, probabilmente nessuno, nemmeno nella stessa azienda, conosce totalmente il funzionamento dei sistemi che regolano le logiche del motore di ricerca.
Certo, cercando online si possono facilmente rintracciare i patents, ovvero i brevetti registrati da Google su strumenti e tecniche utilizzate per sperimentare la maggior parte delle funzionalità che sono visibili nelle SERP del motore di ricerca. Tra l’altro, se non lo conosci, esiste un motore di ricerca (sempre di Google) dedicato esclusivamente all’archiviazione e consultazione di brevetti. Se vuoi farti un giro, lo trovi all’indirizzo patents.google.com (se vuoi vedere invece i brevetti assegnati a Google LLC puoi andare al link https://patents.google.com/?assignee=Google+Inc.).
Oggi però voglio approcciare l’argomento da un punto di vista più “leggero”. Non che quello che troverai in questo articolo sia di comprensione immediata, ma ti garantisco che è molto più semplice della lettura di un paper contenente, ad esempio, le sperimentazioni effettuate sui LLM o sull’addrestamente di BERT (se non sai cos’è, non preoccuparti: te ne parlerò più avanti).
Le informazioni che troverai in questa pagina sono una spiegazione della mini-guida di Google su come funziona il suo motore di ricerca, che trovi in originale qui: https://www.google.com/search/howsearchworks/how-search-works/. Naturalmente non mi sono limitato a tradurre in italiano le informazioni che torvi nella guida, ma ho aggiunto considerazioni e approfondimenti, basati sulla mia esperienza e sulla conoscenza che ho accumulato negli anni della SEO su Google (a proposito, se vuoi approfondire il mio approccio alla SEO puoi andare al post dedicato su “cos’è la SEO“).
Partiremo da una disamina su come funzionano i processi di indicizzazione e ranking del motore di ricerca, per poi analizzare alcuni dei sistemi di ranking più riconoscibili di casa Google. Ancora una volta, se tutte queste parole per te sono poco chiare non preoccuparti: a breve le conoscerai tutte.
Creazione dell’indice dei risultati di ricerca
Come per la maggior parte dei motori di ricerca, si può ridurre il funzionamento di Google in due complessissime attività: l’indexing (in italiano indicizzazione) e il ranking (in italiano posizionamento). Non hai idea di quante volte, tanto nella comunità SEO quanto fra i “non addetti ai lavori”, queste due fasi vengano confuse o usate come sinonimi. Dimmi che non ti è mai capitato di sentire qualcosa come “abbiamo indicizzato in prima posizione la pagina!”.
Al netto del brivido che ho provato anche solo pensando a quanto scritto sopra, quello che è fondamentale sapere è che indexing e ranking sono due cose totalmente differenti. Sono legate consequenzialmente l’un l’altra, ma hanno caratteristiche e funzioni del tutto differenti.
Guardiamole velocemente nel dettaglio.
Indicizzazione, ovvero quello che succede prima della query
Le basi dell’indicizzazione (che, ripeto, è il processo attraverso cui il motore di ricerca inserisce nel suo indice i contenuti che trova nel web) sono ben note. Google cerca tra centinaia di miliardi di pagine web e altri contenuti memorizzati nell’indice di ricerca per trovare informazioni utili da fornire agli utenti, quando questi effettuano una ricerca inserendo una query nel box delle parole chiave.
Semplificando, quello che accade su base costante è questo:
- Crawling (Scansione): i crawler sono dei software che visitano in automatico le pagine web accessibili pubblicamente e seguono i link su tali pagine. Passano da una pagina all’altra seguento i link e archiviano informazioni su ciò che trovano sulle pagine visitate e da altri contenuti accessibili pubblicamente nell’indice della Ricerca Google. La scansione è un processo ciclico e continuativo: i crawlers sono costantemente alla ricerca di contenuti nuovi o aggiornati;
- Indexing (Indicizzazione): quando i crawler trovano una pagina web, i sistemi di Ranking (vedremo fra non molto cosa sono) visualizzano i contenuti della pagina come farebbe un browser. In questo frangente il crawler prende nota soltanto dei segnali principali, dalle parole chiave all’aggiornamento del sito web. Queste informazioni vengono inserite nell’indice Google di risultati. La dimensione totale delle pagine nell’indice Google supera i 100.000.000 di gigabyte.
Ai fini di informazione è importante sapere che, ancora prima della fase di crawling, esiste una fase detta di scheduling, una sorta di “programmazione” delle attività dei vari bot che scansionano il web.
Tutto questo succede spontaneamente. Certo, i SEO possono intervenire per facilitare il lavoro di scansione e indicizzazione dei contenuti, attraverso varie tecniche e accorgimenti da applicare sui siti web. Tuttavia, ricorda che Google indicizza le pagine web senza alcun bisogno che un SEO faccia qualcosa di particolare. Non ci sono magie o “trucchetti”: a meno che tu non abbia bloccato la scansione dei tuoi contenuti o li abbia segnalati come “da non indicizzare”, nella maggior parte dei casi Google fa il lavoro da sé.
É chiaro che, se sai cosa stai facendo, puoi fare in modo che Google comprenda esattamente che tipo di contenuto sta indicizzando, di cosa parla e come distinguerlo da altri contenuti simili del tuo sito. Anzi, è fondamentale far sì che Google indicizzi le pagine giuste per gli argomenti giusti, attraverso la corretta distribuzione di topic via query all’interno dei tuoi contenuti. Questo è quello che può fare un SEO per te, in questa fase.
A livello di puro indexing, tuttavia, parliamo di un processo spontaneo. Se ti dicono che “ti indicizzeranno il sito”, o stanno confondendo i termini indexing e ranking o, peggio, ti stanno vendendo qualcosa di cui nella maggior parte dei casi non hai bisogno.
Se vuoi approfondire queste tematiche, ti rimando al mio articolo “Scansione e indicizzazione di un sito su Google“.
Ranking, ovvero quello che succede dopo la query
Siamo arrivati alla fase che tutti agognano: il posizionamento (o ranking, in inglese). Qui gli sforzi dei SEO di tutto il mondo si concentrano per guadagnarsi le famose “prime posizioni” nelle SERP.
Sono un po’ allergico alla parola posizionamento, in realtà. Più che altro perché, secondo il mio punto di vista, è particolarmente male interpretata. Molti SEO si beano di essere “primi” in una SERP per una determinata parola chiave, senza ricordare che:
- non è detto che la SERP che vedi tu è la stessa che vede un utente a 500 chilometri da te, con una cronologia di navigazione differente, altri cookie nel browser e via dicendo. Le ricerche sono altamente personalizzate e, ahimé, temo che con l’avvento della SGE lo saranno ancora di più;
- siamo usciti dall’era del “posiziono una parola chiave per pagina” da un bel po’. Google è ampiamente in grado di comprendere l’obiettivo di ricerca degli utenti. E questi obiettivi si materializzano ormai con un’infinità di query che hanno lo stesso obiettivo. Se hai posizionato una query per un contenuto e ne hai perse 10 (perché non le hai semplicemente prese in considerazione o perché qualcosa nel percorso è andato storto), non va poi così bene;
- come fai a sapere che la query per cui hai posizionato il contenuto è quella che importa di più agli utenti? Quella più vicina alla conversione? Quella che rimarrà così com’è nel tempo?
Insomma: parlare di posizionare parole chiave è semplicemente una riduzione delle possibilità della SEO oggi. Uno spreco, qualcosa che non dovrebbe né essere decantato, nè tanto meno venduto.
Tornando però al ranking per come lo intende Google.
- Ranking (Posizionamento): a seguito della query digitata dall’utente, i sistemi di Ranking compongono la SERP di Google, classificando i risultati di r-icerca con un mix di:
- segnali di ranking immagazzinati durante il processo di indexing;
- segnali di ranking identificati in modo contingente la digitazione della query (ad esempio, i fattori Offsite più recenti).
L’indice di ricerca di Google è composto da più indici differenti, che intervengono per archiviare differenti tipologie di informazioni da svariate fonti non necessariamente online. Video, immagini, testi e altri dati vengono poi conglobati all’interno della Universal Search.
Alcune delle fonti di archiviazione di cui dispone Google per la costruzione del suo indice sono:
- scansioni del web tramite crawler;
- collaborazioni con enti terzi;
- feed di dati;
- Knowledge Graph, nominata “enciclopedia dei fatti”.
Come funziona il ranking dei risultati di ricerca?
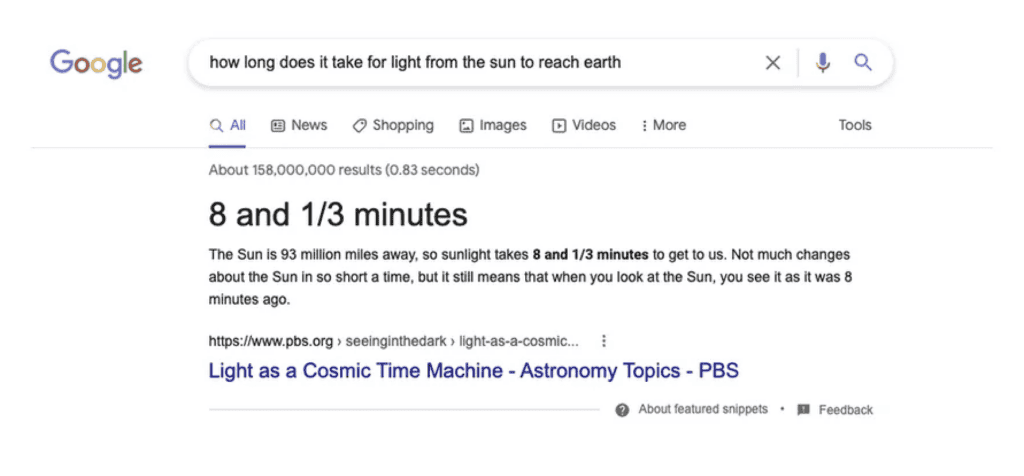
Google raccoglie dai contenuti nel suo indice dei segnali, detti Ranking Signals. Questi segnali sono “captati” e analizzati dai suoi sistemi di Ranking e forniscono un ordine classificato ai contenuti presenti nell’Indice Google ogni qual volta un utente digita una query nella query box di google.com.
I principali segnali di ranking dichiarati da Google possono essere suddivisi per categoria.
- Significato
- Pertinenza / Rilevanza
- Qualità
- Usabilità
- Contesto
1. Significato (Search Intent)
“Per fornire risultati pertinenti, dobbiamo prima capire cosa stai cercando, ovvero l’intento della tua ricerca. A tale scopo, costruiamo modelli linguistici per cercare di comprendere in che modo le parole che hai inserito nella casella di ricerca corrispondano ai contenuti più utili a disposizione”
fonte: https://shorturl.at/cdP69
La comprensione del significato della ricerca riporta al concetto di Search Intent per come è attualmente inteso dalla maggior parte della comunità SEO: l’identificazione non tanto del significato “in sè” della query che l’utente digita, quanto dell’obbiettivo della sua ricerca in Google.
Questo processo passa da informazioni piuttosto semplici, come la correzione di mispelling e errori di ortografia, all’intuizione del valore che termini sinonimici assumono all’interno di una frase. Ovvero, quanto è simile cercare “cambiare luminosità del display” a “regolare luminosità del display”?

La quantità di segnali per la classificazione dei risultati è immensa, e la maggior parte di essa è strettamente legata alla query di ricerca e ai sottintesi che la query stessa porta con sé. I sistemi di Ranking di Google, oltre a comprendere quale risultato sia “il migliore” da fornire all’utente, si occupano anche di capire come questo risultato deve essere servito.
Ad esempio:
- se l’utente cerca parole come “cucinare” o “immagini”, i sistemi di ranking prediligono risposte legate, ad esempio, a ricette o a immagini;
- se l’utente cerca in francese, i sistemi forniranno prevalentemente risultati in francese;
- se l’utente cerca news, i sistemi prediligeranno contenuti freschi piuttosto che contenuti online da tempo e non aggiornati.
2. Relevance (tradotta in italiano come “Pertinenza”)
La parte base dell’identificazione della pertinenza/rilevanza dei contenuti è ancora nel matching fra:
- query digitata dall’utente;
- identificazione, in fase di Indexing, di termini nelle parti rilevanti dei contenuti delle stesse query.
Rispetto alla preistoria della storia dei motori di ricerca, la corrispondenza fra query digitata e parole contenute in un documento web non è più l’unico fattore a determinare pertinenza, pur mantenendo una sua decisa importanza.
Fra le altre fonti di rilevanza che Google ammette di usare, possono essere trovati dati aggregati e anonimi sulle interazioni degli utenti in SERP per valutare la pertinenza dei risultati per come vengono inseriti nel Ranking. Ergo, se un utente dimostra di non gradire i risultati che Google ha mostrato nella pagina dei risultati di ricerca, questo segnale fornirà ai sistemi di machine learning informazioni sulla (poca) pertinenza dei contenuti classificati nella SERP stessa. Puoi trovare maggiori informazioni a questa URL: https://www.google.com/search/howsearchworks/how-search-works/ranking-results/#relevance.
3. Qualità dei contenuti
Il terzo passaggio nell’ordinamento dei risultati nelle SERP, superate la contestualizzazione determinata dal Search Intent e la rilevanza rispetto al Topic, è la valutazione della qualità dei contenuti.
Qui entriamo in un vero e proprio ginepraio, dovuto all’inconsistenza fattuale fra le dichiarazioni che Google lascia trapelare a proposito di come vengono valutati i risultati in SERP e le evidenze che si osservano nelle SERP stesse, dove i risultati in posizioni preminenti spesso violano, in parte o del tutto, le linee guida del motore di ricerca.
Rimanendo alla pura “ottica Google”, parlare di qualità significa comprendere se il contenuto è utile per l’utente, attraverso l’identificazione di elementi che sottolineino, da parte del proprietario del contenuto, i fattori comunemente noti dell’EEAT. Se non sai di cosa sto parlando, ti dico intanto che EEAT è uno dei principi secondo cui i quality raters di Google valutano se un contenuto è utile o si avvicina pericolosamente allo SPAM.
Questi 4 cardini su cui si fonda la valutazione dei contenuti sono:
- Esperienza (Experience)
- Competenza (Expertise)
- Autorevolezza (Authoritativeness)
- Affidabilità (Trustworthiness).
Non scendo nello specifico dell’EEAT in questo post, ma troverai le informazioni sull’argomento in un post dedicato.
4. Usabilità
L’usabilità delle pagine web è il successivo step di analisi dei sistemi di Ranking. A parità di pertinenza e qualità dei contenuti, l’accessibilità delle pagine web può rappresentare un fattore di vantaggio di un contenuto rispetto ad altri.
I fattori di usabilità sono molteplici. Credo che tu ne possa intuire molti già da te, ma ecco alcuni tra i più noti:
- responsività, intesa come presentazione dei contenuti su dispositivi con qualsiasi risoluzione;
- velocità di caricamento dei contenuti, sia nella versione mobile (prioritaria), che desktop;
- accessibilità intesa in senso stretto, come ottimizzazione della pagina per diversamente abili;
- qualità di fruizione della pagina, valutata attraverso la presenza di banner, popup o altri elementi che disturbano la navigazione.
Tra l’altro Google ha rilasciato anche un approfondimento su come auto-valutare la Page Experience delle proprie pagine, disponibile gratuitamente alla pagina della loro guida per i developers: https://developers.google.com/search/docs/appearance/page-experience.
Dagli una letta: non è mind blowing, specialmente se già lavori nel web, ma sono comunque spunti di riflessione interessanti.
5. Contesto e impostazioni di ricerca
Torniamo a quanto dicevo poco fa a proposito dell’esperienza di navigazione personalizzata. Com’è ovvio aspettarsi, tanto più si è immersi nel mondo Google, tanto più i risultati di ricerca verranno ordinati in modo personalizzato.
Alcuni dei segnali personalizzati che influenzano il Ranking dei risultati di Google:
- geolocalizzazione, rilevata da mobile attraverso lo Smartphone e da Desktop sulla base della connessione utilizzata;
- cronologia di ricerca dell’utente;
- dati raccolti dall’account Google, se ad esempio l’utente è loggato nel suo account attraverso il browser che utilizza per navigare.
Ranking Systems (o Sistemi di Ranking)
I sistemi di Ranking (o Ranking systems) sono sistemi automatizzati, che sfruttano AI e Machine Learning, per valutare i contenuti del web e fornire i segnali necessari alla creazione della classifica dei risultati di ricerca nelle SERP di Google.
É necessario considerare almeno due caratteristiche principali, quando si parla di sistemi di Ranking:
- qual è il loro target. I sistemi di Ranking sono peculiari, ciascuno prende in considerazione un aspetto specifico fra i tanti che determinano la qualità dei contenuti pubblicati nelle pagine web, o dei siti web in generale;
- qual è la loro area d’azione. Alcuni sistemi sono sitewide, ovvero agiscono sull’intero sito web e non sullo specifico contenuto. Altri sono invece page-based, quindi basati sulla valutazione di elementi all’interno di una singola pagina di un sito web.
RankBrain
Lanciato nel 2015, RankBrain è stato il primo sistema di AI integrato nella ricerca Google.
L’obiettivo era “semplice”: legare le parole a dei concetti. Attraverso la scansione del web, l’analisi dei contenuti e la comprensione delle parole legate al contesto (sia interno al contenuto, sia fra differenti documenti), RankBrain ha creato una sorta di vocabolario di entità, che gli ha permesso di comprendere (probabilmente complice anche il Knowledge Graph) come i termini si sposano agli altri termini permettendo al significato figurato di essere compreso quanto quello letterale.
Neural Matching System
Google ha introdotto il Neural Matchin System, un sistema di Intelligenza Artificiale, grosso modo nel 2018. Questo viene applicato alla SERP per meglio comprendere come una query è “legata” a una pagina.
L’obiettivo delle reti neurali legate alle SERP è quello di abbinare query complesse e non necessariamente contestualizzate (perché troppo generiche o troppo specifiche) a determinati contenuti, per comprendere meglio quali contenuti rispondano meglio a quali query di ricerca.
Le reti neurali si occupano, tra le altre cose, anche dell’identificazione dei Sub Topic all’interno dei contenuti. Ti ricordi quando parlavo delle altre query, che sfuggono ad alcuni SEO quando si vantano di “aver posizionato una keyword”? Ecco, facevo riferimento a questo. Parliamo del 2018, non di ieri.
Quando un contenuto parla di un topic molto ampio, le reti neurali lo analizzano per comprendere la pertinenza del contenuto stesso per micro-argomenti rientranti nella stessa intenzione di ricerca.

BERT (o Bidirectional Encoder Representations from Transformers)
“With the latest advancements from our research team in the science of language understanding–made possible by machine learning–we’re making a significant improvement to how we understand queries, representing the biggest leap forward in the past five years, and one of the biggest leaps forward in the history of Search”
fonte: https://blog.google/products/search/search-language-understanding-bert/
BERT è un language model, ovvero un modello probabilistico di un linguaggio naturale in grado di generare probabilità di una serie di parole, sulla base di corpora di testo in una o più lingue su cui è stato addestrato.
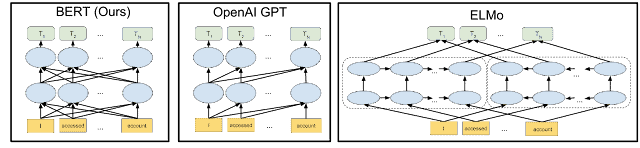
É uno dei sistemi di Ranking Google basato su AI, operativo dal 2019, sviluppato per cercare di comprendere come differenti combinazioni di query possano esprimere intenzioni di ricerca affini o discordi.
Di fatto, l’obiettivo di BERT è comprendere come quale sia il contesto dietro le query di ricerca digitate dagli utenti per reperire informazioni nella ricerca Google.
Per approfondire l’essenza e il funzionamento di BERT, è disponibile una guida Google datata 2018 sul processo di Pre-Training del Natural Language Processing.
Deduplication System
Sistema che si occupa della pulizia di contenuti molto (o troppo) simili fra loro.
L’obiettivo del sistema di deduplicazione è quello di identificare pagine, post o contenuti in generale troppo simili fra loro, e di definire quali devono essere pubblicati nelle SERP di Google e quali possono essere ignorati e pubblicati nelle parti più basse delle SERP.
EMD (Exact Match Domain) System
Il presupposto è che le query inserite nel nome dominio sono un fattore di Ranking. A parità di ottimizzazione e autorità di Brand, “negoziodiscarpebologna.it” dovrebbe avere un lieve vantaggio rispetto a “boutiquedellasuola.it” (supponendo che “La Boutique della Suola” sia un negozio che vende scarpe a Bologna).
Google ha ovviamente interesse nel contestualizzare il peso dell’Exact Match Domain all’interno dell’ampio range di segnali di Ranking estratti dai siti web. Non può rischiare che gli EMD abbiano un peso eccessivo, rispetto ai domini che non contengono query. Anche perché vi garantisco che gli EMD sono tutti acquistati da un bel pezzo!
L’EMD System ha quindi l’obiettivo di bilanciare il peso dell’Exact Match Domain con tutti gli altri segnali di Ranking che un sito offre, per rendere credibile la potenza del nome dominio rispetto agli altri elementi che compongono la qualità del risultato.
Freshness System
Per alcuni argomenti, la velocità e la puntualità della pubblicazione di un contenuto può avere un peso non indifferente. Ad esempio se si ragiona sui contenuti giornalistici di qualsiasi tipo: news, informazioni su un evento sportivo, dati legati a un nuovo film o qualsiasi informazione che rientri nella sfera giornalistica.
Il Freshness System si occupa di raccogliere segnali sulla freschezza dei contenuti, partendo dal presupposto che – in casi in cui la notizia è nuova – vengano privilegiati contenuti nuovi (o aggiornati) al posto di contenuti con un’anzianità che non presentano alcun aggiornamento.
Helpful Content System
Il sistema di Google che valuta la qualità dei contenuti che rispondono alle query di ricerca. É strettamente connesso al concetto di EEAT, inteso come linee guida per la valutazione dei contenuti pubblicati sui siti web. É il sistema di cui vi ho accennato poco più su, presentandolo come uno dei criteri principali per la valutazione della qualità dei contenuti.
L’obiettivo dell’Helpful Content System è quello di stabilire se i contenuti siano effettivamente utili per l’utente in funzione della ricerca effettuata. Prende in considerazione un’enormità di fattori difficilmente misurabili (come l’autorevolezza, la competenza e l’esperienza di chi scrive, la rilevanza dei contenuti sul topic, la frequenza di pubblicazione e simili), raggiungibili attraverso azioni interne al sito (completezza dei contenuti, link interni, esaurimento dei topic trattati) che esterni (link in ingresso, menzioni, diffusione su altre piattaforme, anche offline).
Aggiornato 2024: a partire dal March Core Update 2024, l’Helpful Content System è stato inglobato all’interno del Core System. Questo significa che la qualità dei contenuti viene valutata a livello generale, non più (soltanto) con un algoritmo dedicato.
Link Analysis Systems + Page Rank
I link in ingresso rivestono ancora un ruolo fondamentale all’interno dei segnali di Ranking di Google.
Nel 1998, l’algoritmo del Page Rank fu la vera svolta per la valutazione dell’autorevolezza dei contenuti. Oggi, i sistemi di analisi dei link valutano in modo molto più approfondito come i siti interagiscono da soli, evidenziando e scoprendo relazioni fra contenuti web che linkano o vengono linkati.
L’obiettivo dei sistemi di analisi dei link è ovviamente quello di prevenire la manipolazione del Ranking nella ricerca Google tramite le pratiche di link building e SPAM.
Local News Systems
Anche in questo caso, si fa riferimento a molteplici sistemi di Ranking che identificano e organizzano le news quando sono legate a una determinata Geolocalizzazione.
É ovviamente legato all’ubicazione fisica dell’utente. Se un utente cerca notizie di calcio ed è geolocalizzabile nell’area di Bologna, con molta probabilità visualizzerà informazioni legate al Bologna F.C..
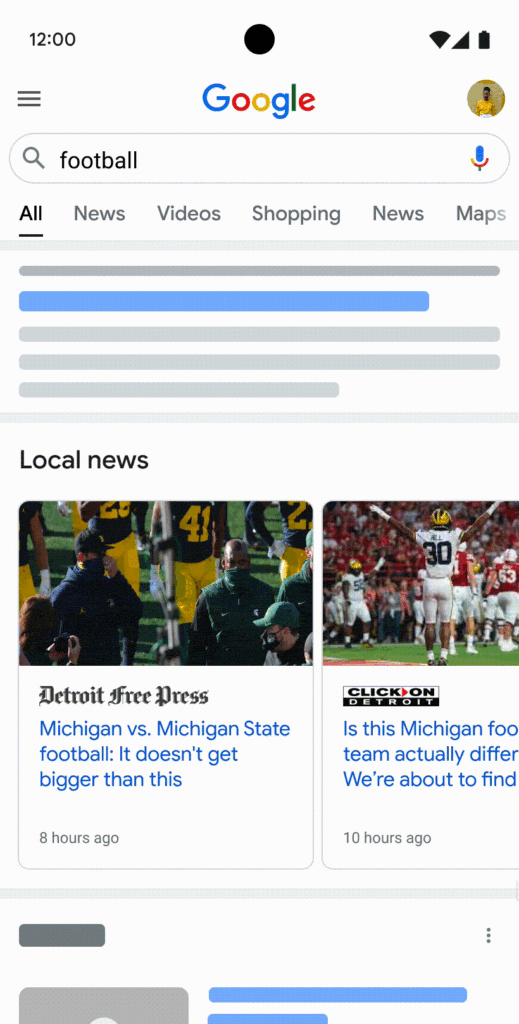
L’obiettivo dei sistemi di Local News è raccogliere le notizie dell’area di interesse dell’utente attraverso due particolari sezioni: “Local News” e “Top Stories”.
Original Content System
É il sistema di Ranking di Google che opera soprattutto nei casi di ri-condivisione dei contenuti di terze parti. É particolarmente sfruttato in casistiche come le pubblicazioni scientifiche o i contenuti giornalistici, dove sono diffuse la necessità e l’abitudine di riportare quanto detto da altri.
L’obiettivo del sistema che valuta i contenuti originali è quello di attribuire correttamente la fonte, identificando chi è il produttore originale del testo e bilanciare correttamente il peso che il testo “duplicato” ricopre nelle varie pagine in cui è collocato.
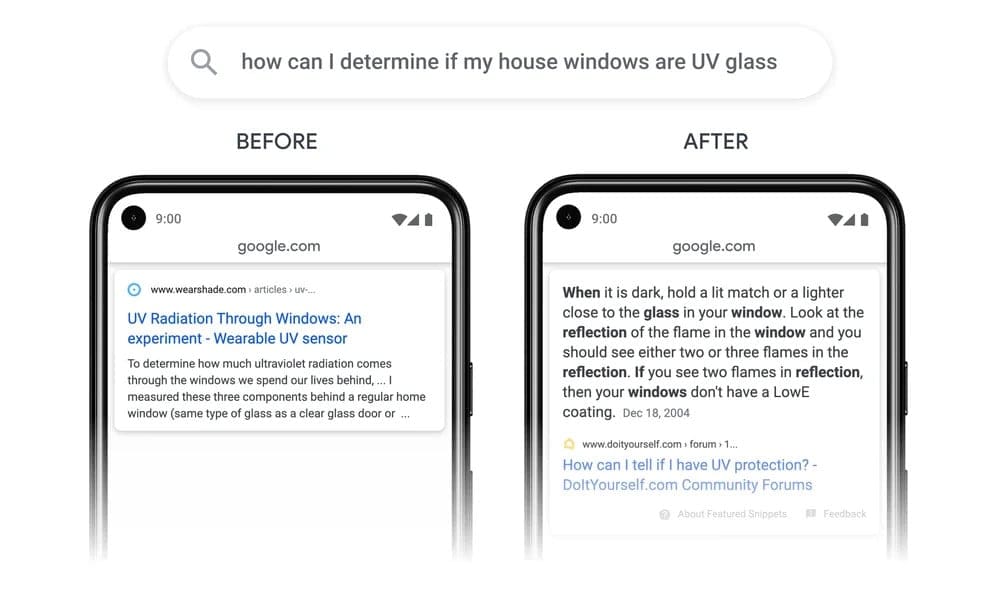
Passage Ranking System
La capacità di rispondere in maniera corretta ed esaustiva è nell’interesse principale del motore di ricerca. Ne consegue logicamente che anche lo specialista SEO si concentri sul rendere pertinente un contenuto per un Topic, i suoi Subtopic e le query di ricerca che forniscono l’ecosistema dell’argomento.
Uno dei pilastri dell’ottimizzazione SEO è da sempre l’ottimizzazione del contenuto univoco (unique content), ovvero la porzione di testo peculiare di un contenuto. Quella che non è rintracciabile in nessun altro contenuto online, che fornisce al motore di ricerca l’indicazione generale del contenuto della pagina.
Andando oltre il concetto di singolo Topic (o Keyword) per pagina, ormai obsoleto nella maggior parte delle ricerche Google, l’obiettivo del Passage Ranking System è quello di identificare la pertinenza di specifici passaggi all’interno del testo non soltanto per il topic principale, ma anche per subtopic trattati in modo più o meno estensivo all’interno del documento.
Reliable Information Systems + MUM (Multitask Unified Model)
Google dispone di una serie di sistemi, non meglio specificati, che si occupano di verificare quanto l’informazione fornita in un documento si attendibile. Questo sposa la necessità del motore di ricerca di apparire come una fonte affidabile di informazione per gli utenti, concetto su cui ruota la maggior parte dei suoi sistemi di monetizzazione (primo fra tutti Google Ads).
Molti di questi sistemi sono basati sul concetto di consenso (consensus-based technique), ovvero la capacità di identificare come vera un’informazione qualora tantefonti autorevoli la presentino allo stesso modo.
L’obiettivo dei sistemi di affidabilità delle informazioni è quindi da un lato comprendere se un’informazione è vera; dall’altro, di avvisare l’utente – attraverso banner o testi specifici direttamente in SERP, quando Google non ha abbastanza dati per comprendere se un’informazione è da ritenere affidabile o meno.
MUM è il sistema basato su AI che maggiormente è in grado di effettuare analisi basate sulla tecnica del consenso, in grado di comprendere la veridicità di un’informazione anche se questa viene trattata attraverso differenti parole, che coinvolgono differenti concetti/rappresentazioni della stessa informazione.
Reviews System
Le recensioni degli utenti a proposito di un’informazione, un prodotto o un servizio sono un segnale di Ranking piuttosto forte, perché certificano l’apprezzamento (teoricamente) imparziale di un utente verso un Brand. Per ovvi motivi, la manipolazione delle recensioni è probabilmente sentita tanto quanto la manipolazione del ranking via backlink.
L’obiettivo del sistema delle recensioni è quello di comprendere e contestualizzare le recensioni ricevute da un Brand, per identificare alcuni dettagli come la veridicità della recensione e il suo peso specifico, legato a chi l’ha rilasciata (expertise, autorevolezza e simili).
Site Diversity System
“Our site diversity system works so that we generally won’t show more than two web page listings from the same site in our top results, so that no single site tends to dominate all the top results.”
Fonte: https://developers.google.com/search/docs/appearance/ranking-systems-guide
Non è inusuale trovare, nelle SERP, risultati multipli legati allo stesso dominio. Tendenzialmente ciò non dovrebbe accadere: Google ha interesse a mostrare differenti aspetti di una stessa informazione, ovvero diverse voci che esprimono opinioni e dati, apportando valore alle SERP.
Allo stesso modo, è tutt’altro che raro trovare molteplici risultati legati allo stesso dominio. Fino a metà del 2023, questi erano spesso indentati: ciò significa che nelle SERP era visualizzato un risultato legato a un dominio e, subito sotto con un leggero rientro a destra, un secondo risultato dallo stesso sito web. A partire dalla metà del 2023, Google ha modificato il layout dei risultati multipli in SERP, tanto che ora risultati differenti dello stesso dominio sono ampiamente rintracciabili in posizioni anche molto separate.
L’obiettivo dei sistemi di differenziazione dei siti è quello di rendere le SERP non monopolizzate da un determinato Brand e lasciare libera la possibilità di scegliere da chi informarsi. Ovviamente, per SERP dominate da Brand o per specifiche query, è più che probabile trovare nella SERP risultati di un unico dominio (ad esempio, per le query Navigazionali o Branded).
Lato SEO, un’informazione importante su questo sistema di Ranking è che tratta i subdomains come fossero lo stesso sito. Ovvero, se la stessa informazione è contenuta in sito.it/pagina e subdomain.sito.it/pagina, considererà tendenzialmente solo uno dei due per il Ranking.
SPAM Detection Systems
Google ha molteplici sistemi in grado di rilevare la diffusione di contenuti SPAM o non utili, finanche nocivi. Alcuni sono algoritmici, altri sono manuali (ad esempio il team dei Quality Raters, deputato a identificare contenuti di bassa qualità e segnalargli a Google).
Fra i più potenti sistemi di rilevamento dello SPAM c’è SpamBrain, lanciato nel 2018 e AI-based.
L’obiettivo dei sistemi di rilevamento dello SPAM sono molteplici: dal limitare le manipolazioni all’algoritmo di ricerca Google (soprattutto nel contesto della Link Building, estremamente osteggiata da Google), al proteggere gli utenti online da truffe, frodi e molestie.
Conclusioni
Come ci si poteva aspettare, il funzionamento di Google è tutt’altro che semplice. Oltretutto, l’azienda è giustamente molto restia a rilasciare informazioni troppo dirette sulle logiche che regolano i suoi sistemi, considerata la tendenza dei professionisti del settore a manipolarle per i loro scopi.
A Google viene spesso rimproverata una poca chiarezza sulle dinamiche che regolano il suo potentissimo e usatissimo motore di ricerca. Io stesso, parlando poco fa della valutazione dei contenuti utili, ho espresso dubbi sull’effettiva validità dell’Helpful Content System alla luce dei risultati che si trovano nelle SERP in posizioni dominanti.
Tuttavia, Google ci ricorda quanto segue:
Vogliamo essere trasparenti sul funzionamento della Ricerca, ma dobbiamo fare anche attenzione a non rivelare troppi dettagli che permetterebbero di manipolarne i risultati e di peggiorare l’esperienza per tutti.
È una lezione che abbiamo imparato a nostre spese: nel 1999 i fondatori di Google pubblicarono un articolo su PageRank, un’importante innovazione dell’algoritmo di Google. Dopo che l’articolo venne pubblicato, molti spammer cercarono di manipolare Google pagandosi tra loro per i link.
La Ricerca è uno strumento potente. Aiuta le persone a trovare, a condividere e ad accedere a un’enorme quantità di contenuti a prescindere da come si colleghino e da dove si trovino. Lavoriamo sodo per garantire risultati di ricerca di alta qualità e non spam. Miglioriamo costantemente le nostre tecnologie di lotta allo spam e continueremo a lavorare a stretto contatto con webmaster e altri enti per incoraggiare e supportare un ecosistema web di alta qualità.
Fonte: https://www.google.com/search/howsearchworks/how-search-works/detecting-spam/
Prova a immaginare una realtà in cui la più grande banca dati di informazioni del mondo sia facilmente manipolabile. Pensa a quanto sarebbe pericoloso e insicuro per le persone cercare informazioni su Google.
Sicuramente è una questione economica. Se Google non avesse la sua autorevolezza a garantire la qualità delle informazioni che offre agli utenti, probabilmente sarebbe fallito da molto tempo, come altri motori di ricerca prima di lui.
Mi piace però pensare, ancora oggi, che alla base dell’azienda Google ci siano ancora delle menti, se non proprio dalle inclinazioni umanitarie, quanto meno responsabili di quanto il loro prodotto può al contempo aiutare o danneggiare moltissimo il mondo.



