

L’indicizzazione è l’attività attraverso cui Google e gli altri motori di ricerca inseriscono i contenuti di un sito web all’interno del loro archivio di risultati.
Spesso confuso con il termine posizionamento, l’indexing ha in realtà un ruolo completamente diverso e viene svolta in un momento totalmente differente rispetto. É lo step precedente al posizionamento in SERP, quello che permette ai tuoi contenuti e alle tue pagine di competere nelle pagine dei risultati di ricerca.
La conditio sine qua non, potremmo dire. Se una pagina non è nell’indice Google, la conseguenza logica è che non la troverai mai all’interno dei risultati classificati in SERP.
Se non hai ben chiaro cosa sia e come funziona l’indexing di Google questo è l’articolo che fa per te. Cercherò di mostrarti (in termini semplici) cos’è l’indicizzazione per un motore di ricerca, in quale fase del processo di ottimizzazione SEO si inserisce e cosa puoi fare per agevolare i motori di ricerca nell’archiviare i tuoi contenuti nel loro indice.
Una breve ma fondamentale premessa
Un po’ di contesto, per permetterti di comprendere al meglio il contenuto di questo articolo.
Nella stragrande maggioranza dei corsi, dibattiti, post e confronti sulla SEO, la maggior parte dell’attenzione viene data al ranking. Si parla di fattori di ranking, segnali di ranking, rankare in prima pagina o in prima posizione, e via dicendo.
Il ranking (o posizionamento, tradotto in italiano) è senz’altro importante, come step nel processo di ottimizzazione. Tuttavia, fra le fasi che collegano direttamente un contenuto al motore di ricerca, è soltanto l’ultimo dei passaggi.
Il processo di creazione del ranking di Google passa attraverso tre fasi ben distinte: scansione, indicizzazione e posizionamento.
Definendo questi termini, è importante che tu sappia che:
- per scansione, si intende la “scoperta” e il download di nuove pagine da parte dei crawler di Google (se non sai cos’è un crawler non preoccuparti, ne parlerò a breve);
- per indicizzazione, si intende il processo per cui le pagine vengono analizzate e inserite nell’indice;
- con posizionamento si fa riferimento al ranking dei risultati nelle SERP, ovvero la classifica generata dal motore di ricerca quando un utente cerca una keyword o una query.

Se vuoi approfondire la panoramica generale del funzionamento di Google, del processo e dei suoi sistemi di ranking (core system e ranking systems), trovi maggiori informazioni in questo articolo che ho scritto qualche tempo fa: “Come funziona la ricerca Google“.
In questo post, come ti ho anticipato nell’intro, ci soffermeremo sui concetti di crawling e indexing, e su come muoversi per ottimizzarli al meglio.
Crawling: la scansione (o individuazione) degli URL
La fase di scansione, o crawling, è la fase di individuazione degli URL.
Google e gli altri motori di ricerca scansionano continuamente il web con i loro crawlers (ovvero software e programmi di scansione), per trovare nuovi contenuti da aggiungere al proprio indice. Dopo la “scoperta” di un contenuto, il crawler (detto anche bot, robot o spider) passa alla fase di indicizzazione: analizza tutto ciò che trova nella URL e archivia la pagina (o il medium, inteso come immagine, video o file), nell’indice generale del motore di ricerca.

Questo processo avviene attraverso le URL. Per identificare nuovi contenuti, i bot si spostano da un’URL all’altra sfruttando i link che rintracciano all’interno delle risorse che stanno analizzando.
Per intenderci: se il bot di Google sta scansionando una pagina del mio sito e in questa pagina trova un certo numero di link, con molta probabilità programmerà (o metterà in “Scheduling“) di andare ad analizzare anche le URL di destinazione di tali link.
E così via, in un processo pressoché infinito. E continuo, perché i crawler non passano su una pagina soltanto una volta ma ciclicamente.
La prima cosa che devi accertarti, quando metti online dei contenuti, è che questi siano effettivamente scansionabili dai crawlers dei motori di ricerca.
Quanti crawler utilizza Google?
Google dispone di un numero impressionante di crawler per scansionare il web, ognuno con una sua funzione specifica.
I più noti sono senza dubbio Googlebot Smartphone e Googlebot Desktop, utilizzati rispettivamente per la scansione dei contenuti da mobile e in formato desktop.
Googlebot Smartphone, in particolare, è senz’altro il più temuto e amato crawler di casa Google. Ad ottobre 2023, infatti, è stato annunciato il completamento del passaggio all’indicizzazione mobile-first. Ciò significa che Google, per l’indicizzazione dei contenuti, da priorità al crawler che lavora su Smartphone.
Attenzione: questo non significa che le varianti desktop dei siti web non siano importanti o vadano trascurate, a favore del mobile. Prendetevi cura dei vostri siti a tutto tondo, sempre.
Oltre ai crawler sopracitati, ne esistono tuttavia molti altri, deputati a raccogliere informazioni su differenti media e/o materiali reperibili per il web: Google Image per la scansione delle immagini per Google immagini e per i prodotti, Google Video per la scansione dei formati video, Google News per le scansioni di articoli e notizie… e via dicendo.
Se vuoi approfondire tutti i bot, vuoi sapere come identificarli a livello di Token o avere altre informazioni in merito, ti consiglio di approfondire l’articolo della guida di Google Search Central relativa ai crawler, che trovi qui: https://developers.google.com/search/docs/crawling-indexing/overview-google-crawlers.
Come bloccare o favorire la scansione dei contenuti
La scansione è il primissimo processo da tenere in considerazione quando si decide di sporcarsi le mani con la SEO. In differenti casi del lavoro su un sito web, può essere necessario decidere di “impedire” la scansione dei contenuti. In altri, massimizzare le possibilità che un contenuto venga scoperto velocemente, per essere inserito rapidamente nell’indice e (si spera) rankare il prima possibile.
Bloccare la scansione
Per fare questo, puoi usare il file Robots.txt, impostando la direttiva Disallow in corrispondenza del bot che vuoi bloccare. Ad esempio, se vuoi chiedere al bot di Google di non scansionare tutto il tuo sito web, dovrai aggiungere nel tuo file robots.txt quanto segue:
User-agent: Googlebot
Disallow: /
In questo modo, stai dicendo al bot che non vuoi che lui scansioni le tue URL.
Puoi bloccare anche intere sezioni del tuo sito web, ma lasciarne disponibili alla scansione altre. Ad esempio, se ho una cartella /cartelladanonscansionare/ in cui ci sono documenti web che non voglio i crawler vedano, posso dire a Google Bot quanto segue:
User-agent: Googlebot
Disallow: /cartelladanonscansionare/
Ovviamente, se vuoi cercare di impedire la scansione a tutti i bot dello scibile, dovrai “chiamare in causa” uno user agent differente: il “*”.
User-agent: *
Disallow: /
Se vuoi approfondire l’argomento (e ti consiglio di farlo se hai intenzione di iniziare a smanettare col file robots.txt, ti consiglio la guida ufficiale di Google. La trovi a questa URL: https://support.google.com/news/publisher-center/answer/9605477?hl=it.
Quando potresti trovarti a usare la direttiva disallow? Un paio di situazioni-tipo:
- il sito è in costruzione, quindi non vuoi che Google veda quello che stai combinando;
- se hai delle sezioni di sito che non vuoi vengano presi in considerazione (ad esempio le URL generate d parametri).
Nota importante: il disallow è una direttiva che riguarda la scansione dei siti web. Usandola, non stai dicendo ai bot di non indicizzare le pagine, ma soltanto di non scansionarle.
Ciò significa che, se una pagina è già online e vuoi toglierla dall’indice (e quindi dalle SERP), non devi usare il disallow, ma il noindex. Se, tuttavia, la pagina non è ancora online (ovvero non è stata mai scansionata e indicizzata da Google), il disallow può essere sufficiente affinché non venga nemmeno indicizzata.
Favorire la scansione dei contenuti
Se la scansione è la fase di individuazione dell’URL e la loro scoperta avviene attraverso i link, è piuttosto facile comprendere quali possano essere le modalità per facilitare il crawling.
In soldoni, puoi/devi:
- ovviamente, non mettere la pagina in disallow (ho visto cose…);
- linkarla dal tuo sito (le pagine orfane, ovvero non linkate da nessuna parte, hanno ovviamente più difficoltà ad essere trovate dai bot);
- eventualmente linkarla esternamente al sito;
- aggiungerla alla Sitemap XML.
In linea generale, per favorire la scansione, è importante:
- genare una struttura di navigazione che permetta al crawler di scansionare in profondità il tuo sito web;
- utilizzare elementi come le Breadcrumbs per facilitare il processo di scoperta degli URL interni;
- curare le performance dei server, sia in termini di Core Web Vitals, sia nella prevenzione di errori invalidanti (vedi errori 500 e simili);
- fai attenzione alla dispersione di Crawl Budget, specialmente in siti molto voluminosi (nell’ordine di decine di migliaia di pagine).
Per richiamare l’attenzione del Googlebot alla messa online di un contenuto, puoi utilizzare il tool URL Inspector di Google Search Console.
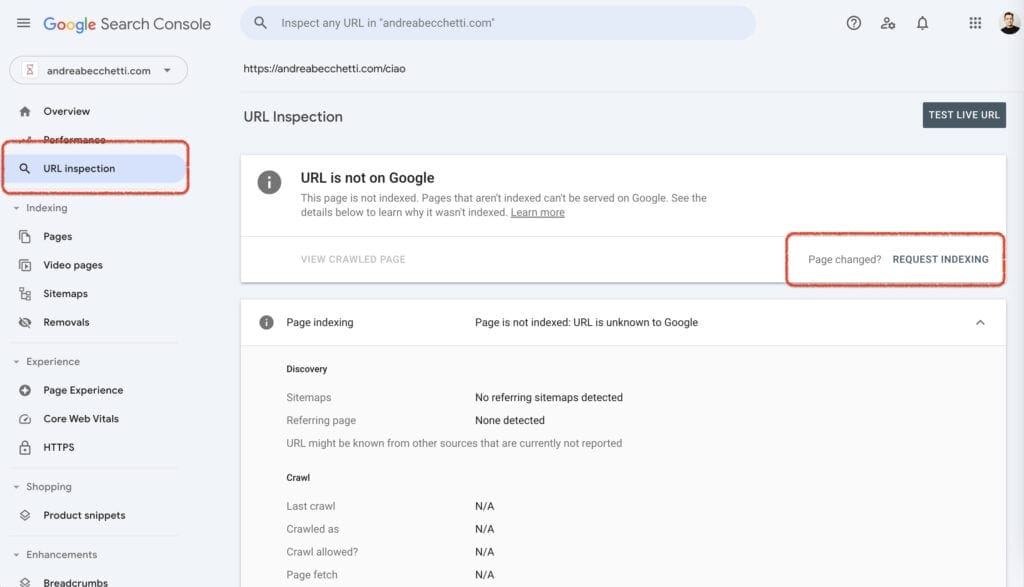
L’esempio è di una URL fittizia del mio sito web. Come vedi, il comando si chiama “REQUEST INDEXING”, ed è quello che generalmente si usa per richiedere l’indicizzazione (e quindi, implicitamente, anche la scansione) di una nuova pagina o di una pagina aggiornata.
Se quello che stai richiedendo è l’aggiornamento, al posto del messaggio “URL is not on Google” troverai le informazioni sulla pagina già in indice.
Ti ho fornito un po’ di soluzioni, ma sappi che Google ormai è capace di scansionare un contenuto entro pochi minuti dalla sua messa online, se viene messo nelle condizioni di farlo (vedi l’elenco soprastante).
Se vuoi sapere quando, per quanto tempo e su quali contenuti il crawler si è fatto un giro, ti consiglio di utilizzare l’analisi dei LOG del tuo server, se hai modo di darci uno sguardo.
Indexing: il processo di indicizzazione dei contenuti
L’indicizzazione Google è il processo attraverso cui il crawler analizza e inserisce nell’archivio del motore di ricerca i contenuti precedentemente scoperti, scansionati e scaricati dal web.
Sento ancora molti dire “voglio indicizzare il mio sito su Google per questa keyword”. Lo ammetto, ogni volta è una piccola pugnalata al cuore.
Al netto che “posizionare (che è il termine corretto) una keyword è un concetto potremmo dire vintage, molto anni 2000, l’indicizzazione è un processo tendenzialmente spontaneo. Il motore di ricerca lo fa a prescindere se alcune condizioni sono rispettate. Condizioni naturali, potremmo dire, per cui il lavoro di un SEO non è indispensabile.
Ho usato le parole “analizza” e “inserisce” non a caso. Sempre semplificando all’estremo il funzionamento di uno degli algoritmi più potenti del pianeta, durante la fase di indicizzazione il crawler si occupa appunto di:
- analizzare i contenuti che trova nell’URL che ha scansionato
- inserirla nell’indice del motore di ricerca in relazione a quello che ha compreso nell’analisi
Se quello che trova durante l’analisi non gli piace, probabilmente il tuo sito non verrà indicizzato, friggendo in quell’atroce limbo che è il “crawled – but currently not indexed”. Ovvero “scansionato – attualmente non indicizzato”.
Ouch.

Non è necessariamente un dramma. A volte le pagine che trovi in questo report devono essere lì, perché sono contenuti che hai deindicizzato, perché Google ha scansionato i Feed ma non ritiene giustamente abbia senso metterli in indice e per tanti altri motivi che onestamente, nonostante faccia SEO da quasi 15 anni, non ho mai davvero capito del tutto.
Alcune cose, semplicemente, non le capiremo mai.
Perché Google non indicizza una pagina?
In altri casi, invece, trovare una pagina in quel report è un gran problema. In generale, le casistiche possono essere davvero tante.
Il primo assoluto, che ti spiego qui prima di inserirlo nell’elenco puntato che seguirà, è che probabilmente il tuo contenuto fa schifo.
Capita, non ci rimanere male, ma in quest’epoca di grande attenzione alla qualità dei contenuti (se vuoi approfondire, anche per questo ho il post che fa per te: Google Helpful Content e qualità dei contenuti).
Se il tuo testo non aggiunge nulla di nuovo rispetto a quanto già presente online, ha porzioni di contenuto duplicati da altri contenuti del tuo sito, se l’hai generato con chatGPT o un’altra AI Generativa e non ti sei impegnato a rivederlo e renderlo utile, può succedere. E nemmeno troppo raramente.
Google ha bisogno di contenuti utili per sopravvivere come motore di ricerca, per vendere spazi pubblicitari, per avere dati con cui far progredire i suoi algoritmi… e chissà quanto altro.
Quindi: qualità, qualità, qualità.

Altri motivi in ordine sparso possono essere:
- problemi di accessibilità: se il crawler di Google non può accedere a una pagina a causa di impostazioni del file robots.txt, errori del server, tempi di caricamento eccessivamente lunghi o se la pagina è protetta da password, è praticamente scontato che la pagina non verrà indicizzata;
- errato utilizzo del noindex: se una pagina include un tag meta noindex o un’intestazione HTTP X-Robots-Tag con valore “noindex”, tendenzialmente Google non indicizzerà la pagina;
- Javascript: Google dichiara che Googlebot scansiona e indicizza correttamente Javascript, ma un uso eccessivo può comunque creare dei problemi. Se vuoi approfondire la fase di rendering, implementata sui siti che fanno largo utilizzo di Javascript, ti consiglio questa risorsa Google.
- violazione delle linee guida per i webmaster: nemmeno a dirlo, se Googlebot rileva tecniche SPAM, cloacking, manipolazione algoritmica o in violazione delle sue linee guida, non aspettarti di trovarla in indice;
- pagine con interstizi invasivi: hai presente quando apri una pagina e riesci a leggere tutto fuorché il suo contenuto? Quei contenuti dove riesci a vedere solo i 3000 popup pubblicitari che si aprono appena l’URL è caricata. Ecco, anche quella può essere una causa di mancata indicizzazione.
- contenuto duplicato: se una pagina che hai pubblicato è molto simile ad altre pagine sul web, Google potrebbe decidere di scansionarla ma non ignorarla. Torniamo al punto 0: per duplicato non si intende i brutale copia/incolla dei contenuti altrui, ma anche un contenuto simile o parafrasato che non dà nulla in più rispetto agli altri trovati nel suo indice;
- problemi di sicurezza: un sito compromesso può vedere i suoi contenuti deindicizzati;
- errori di crawl e server: già citati prima, ma repetita iuvant. Anche una frequenza troppo elevata di errori server (come gli errori 500) può impedire a Google di accedere e quindi indicizzare le pagine.
Per accertarti di non avere problemi di indicizzazione, puoi utilizzare il report delle pagine non indicizzate di Google Search Console.

Non tutto quello che non è indicizzato rappresenta un errore. Nei vari report di questa sezione troverai anche quello che tu hai scelto di indicizzare. In questo caso, nello screenshot del mio sito, trovi ad esempio 3 risorse “escluse in base al tag noindex”, che io stesso ho scelto di non far inserire dall’indice.
Cosa può indicizzare Google
Non dico tutto… ma onestamente poco ci manca.
Nella guida di Google Search Central puoi trovare un intero file con l’elenco delle risorse che googlebot può inserire nel suo indice. Tra le altre, oltre al testo e alle immagini, troviamo PDF, file Excel, file di tipo Google Earth e molto altro ancora.
Perché te lo sto dicendo? Molto semplice: quando decidi quale contenuto fornire ai tuoi utenti, accertati che il motore di ricerca:
- sia in grado di indicizzarlo;
- sia proprio quello che gli utenti stanno cercando.
Se cercano un’informazione riassumibile in un’immagine beh… forse è a quella che devi dare priorità.
Se vuoi approfondire la tematica, ti consiglio di dare uno sguardo al mio post sul Search Intent e la loro analisi per la SEO.
Come favorire l’indicizzazione dei contenuti
In questo caso purtroppo non hai moltissime possibilità. Google stesso afferma che l’indicizzazione è un processo che non ha tempistiche pre-stabilite e anzi può passare del tempo fra la scoperta/scansione di un contenuto e la sua effettiva indicizzazione.
Per approfondire, ti consiglio la lettura di questo contenuto di Google, sempre tratto da Google Search Central: https://support.google.com/webmasters/answer/7474347?hl=it.
In linea di massima, per quella che è la mia non indifferente esperienza nel settore, i modi migliori per favorire l’indicizzazione di una pagina sono i seguenti:
- assicurarsi che la pagina sia scansionabile, come visto in precedenza;
- assicurarsi che tutti i punti che possano impedire l’indicizzazione di una pagina non si verifichino, come visto in precedenza;
- effettuare il submit della nuova pagina a Google via URL inspector in Search Console;
- utilizzare API indexing per favorire l’indicizzazione dei contenuti. Uno strumento molto comodo, che ti permette di richiedere in via prioritaria l’aggiornamento, la rimozione o la richiesta di indicizzazione per URL multiple. Uno po’ complicato da settare, perché prevede la creazione di chiavi API da Google Cloud (insomma, c’è da portare un po’ di pazienza e smanettarci un po’ per usarlo correttamente), ma senz’altro può valerne la pena. Qui trovi la guida di Google all’utilizzo dell’API Indexing.
Fatto questo, per come la vedo io, mettiti l’anima in pace e aspetta.
Due punti importanti sull’indicizzazione
Ho ancora un paio di cose da dirti prima di salutarti. Voglio brevemente parlarti di due argomenti inerenti l’indicizzazione:
- come togliere una pagina dall’indice;
- come gestire l’indicizzazione lato SEO.
Come rimuovere una pagina dall’indice Google
La risposta è semplice, ma merita un piccolo chiarimento.
Per eliminare una pagina dall’indice Google, i migliori metodi che ho testato fino ad oggi sono:
- utilizzare il tag Noindex, che segnala a Google che la pagina non dovrebbe essere sui motori di ricerca;
- cancellare la pagina e gestirla con un codice 410 – gone forever.
In alternativa, puoi anche provare a bloccarla con una password, che ovviamente Google non può scavalcare e che potrebbe essere sufficiente per procedere alla deindicizzazione.
Per l’amore di tutto quello che di sacro e bello c’è al mondo, non usare il disallow per deindicizzare perché semplicemente non funziona.
La direttiva disallow, come abbiamo visto prima, serve per evitare che Googlebot scansioni una pagina. Se una pagina è già in indice, l’unico effetto che avrai sarà quella di non farla più scansionare dal motore di ricerca. Con tutta probabilità, troverai qualcosa di questo genere.
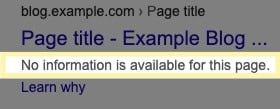
Tieni sempre a mente che Google non è obbligato a tenere in considerazione il noindex (anche se, fortunatamente, nella maggior parte dei casi rispetta l’istruzione).
Come gestire l’indicizzazione lato SEO
Come avrai percepito, ritengo personalmente che la fase di indexing sia molto importante e che, nonostante sia un processo fisiologico del motore di ricerca, in qualche modo un SEO può intervenirvi.
Come farlo è piuttosto “semplice”, nel concetto se non nella messa in pratica. Devi gestire correttamente le intenzioni di ricerca degli utenti, per identificare correttamente i punti di accesso organico che, dalla SERP, possono portare gli stessi utenti sul tuo sito.
Ciò significa comprendere quanti contenuti creare, per quali query ottimizzarli e come strutturarli fra loro. Oltre, ovviamente, a rispondere alla richiesta generando dei contenuti realmente utili, pensati per soddisfare l’obiettivo che si nasconde più o meno esplicitamente dietro alle parole chiave.
Se vuoi approfondire questi argomenti, ti lascio a seguire i link dei post che ho scritto in materia.
- Ricerca di parole chiave (o Keyword Research) per la SEO. Qui trovi i rudimenti per apprendere concettualmente e praticamente il processo di ricerca delle query;
- Search Intent: comprendere l’intenzione di ricerca degli utenti. Qui trovi la mia metodologia su come analizzare e suddividere le query per generare contenuti performanti ed evitare cannibalizzazioni di keyword;
- SEO On Site: come ottimizzare un sito web per i motori di ricerca. In questo post ho parlato di elementi tecnici come strutturazione dei contenuti, breadcrumbs, canonical e simili;
- SEO On Page: l’ottimizzazione dei contenuti. Le indicazioni su come curare l’aspetto SEO dei contenuti;
- Heplful Content e qualità dei contenuti. Un’analisi del meccanismo di valutazione della qualità dei contenuti secondo le linee guida di Google.
Direi che c’è più o meno tutto, o almeno quello che è essenziale. Mi rendo conto che è un bel po’ di materiale da somatizzare, ma d’altronde l’ottimizzazione per i motori di ricerca è una disciplina tutt’altro che semplice e lineare.
Spero ti torni tutto utile. Se hai dubbi, necessità di chiarimenti o sei in disaccordo con qualcosa, utilizza i commenti e ti risponderò nel più breve tempo possibile!



