

Molto spesso, quando si parla di ottimizzazione SEO per i siti web, si tende a concentrarsi davvero troppo sul contenuto. Indipendentemente dal fare riferimento a una pagina o ad un insieme di articoli, il focus si concentra quasi esclusivamente su quello che l’utente e il motore di ricerca dovranno leggere.
Tuttavia, c’è un passaggio anteriore alla valutazione del contenuto: la sua scoperta e indicizzazione. Se ti sei perso questa due tematiche (scansione e indicizzazione), puoi approfondire la lettura dei due contenuti che ho scritto espressamente per trattarle: sono “Come funziona la Ricerca Google”, che tratta indicizzazione e sistemi di ranking, e “Google Helpful Content System”, che è invece concentrato sui suggerimenti e le indicazioni che Google fornisce per autovalutare la qualità dei contenuti.
In questo articolo, ho deciso di trattare un argomento specifico: quella serie di processi che facilitano la scoperta, la scansione e la comprensione dei contenuti che puoi pubblicare su un sito web.
Parliamo di SEO On Site.
Cos’è la SEO On Site
La SEO On Site è l’insieme di attività che riguardano globalmente l’ottimizzazione di un sito web. Le attività di SEO On Site sono quelle che favoriscono la scoperta di nuovi contenuti da parte del motore di ricerca e la loro corretta indicizzazione.
Ammetto che questa è una definizione piuttosto arbitraria e dai riflessi fortemente personali. In gran parte del mondo SEO, le attività di On Site e On Page sono considerate fondamentalmente la stessa cosa: l’ottimizzazione del sito dall’interno, in aperta contrapposizione con SEO Off Page, che si occupa invece di tutti quei fattori che derivano da fuori (link, menzioni, citazioni et similia).
A me piace distinguerle perché ritengo abbiano un differente focus.
La SEO On Page è la gestione dei fattori che permettono alle singole pagine di rankare sulle SERP dei motori di ricerca (in termini spicci, parlo di ottimizzazione dei meta-tag, scrittura del contenuto e tutte quelle buone pratiche che trovi nel post sulla SEO On Page), con SEO On Site mi riferisco a una disciplina che guarda al sito dall’alto e si occupa di mettere ogni cosa al punto giusto: creando percorsi adeguati fra i differenti contenuti, stabilendo gerarchie e collegamenti interni, evitando gli sprechi e prevenendo la confusione. Tanto per l’utente, quanto per i crawler dei motori di ricerca.
La SEO On Site è per molti versi la parte più tecnica dell’ottimizzazione per i motori di ricerca, e fortemente concentrata, più che sul posizionamento vero e proprio, sull’indicizzazione e la catalogazione dei contenuti.
Principali elementi di SEO On Site
C’è un vero e proprio microcosmo di ottimizzazioni da fare su un sito web, ancora prima di pensare alla prima riga di testo da buttare giù. Partendo dalle operazioni globali (impostazione dei certificati di sicurezza e redirect global dei contenuti del dominio da www a non-www, o viceversa), fino ad attività one shot (ad esempio, la creazione di una Sitemap XML).
Moltissimi dei siti che ho analizzato nel corso degli anni avevano contenuti validi, a volte buoni profili backlink e, talvolta, interessanti attività a supporto del Brand. Eppure, ve n’era pochissima evidenza in SERP. A volte non ve n’era affatto.
Questo perché la strutturazione SEO del sito era stata sottovalutata. La SEO On Site è un po’ come una ricetta: se prendi gli ingredienti più gustosi, genuini e saporiti che la natura può offrire, ma li getti alla rinfusa in una teglia e spari il forno a 200′ per 3 minuti, non puoi certo aspettarti un capolavoro. Anzi, avrai anche il doppio malus di essere riuscito anche a sprecare degli ottimi elementi.
Ok, fine del terrorismo psicologico. Ora che hai capito (spero) quanto è importante fare ottimizzazione SEO On Site, possiamo passare ad analizzare alcuni dei suoi elementi principali. Non credo riuscirò ad elencarli tutti, ma cercherò di mettere quelle attività che non puoi non mettere in conto quando lavori su un sito web.
Elenco delle (mie) attività On Site prioritarie
Le attività di SEO On Site sono tantissime. Alcune hanno un peso maggiore, altre prese singolarmente sono meno impattanti ma tutte insieme forniscono le fondamenta dell’ottimizzazione SEO di un sito.
In questo post te le elencherò e fornirò una spiegazione sommaria del loro ruolo nelle dinamiche di ottimizzazione. Andrò poi ad approfondirle con dei contenuti dedicati per fornire a ciascuna attività lo spazio che le è dovuto. Puoi considerare i paragrafi seguenti un’introduzione agli elementi di SEO On Site, da usare come una bussola per orientarti nell’operatività.
Questo l’elenco di attività di SEO On Site:
- definizione della struttura di navigazione
- gestione delle breadcrumbs
- gestione dei permalink
- impostazione dei canonical
- gestione delle pagine dinamiche
- gestione dei link interni
- impostazione della sitemap
- utilizzo di noindex e nofollow
- disallow da file robots.txt
- gestione dei tag
- inserimento dei dati strutturati
- ottimizzazione delle performance e dei core web vitals
Proprio un bel po’ di cose da fare, vero? Analizziamole più da vicino.
Struttura di navigazione
É uno degli aspetti più importanti per garantire che i tuoi contenuti vengano scoperti, tanto dagli utenti quanto dai motori di ricerca.
Gestire correttamente cartelle e sottocartelle all’interno di un dominio permette al crawler del motore di ricerca di trovare e ri-trovare i contenuti facilmente. E questo, come immagini, è importantissimo affinché tutte le pagine del tuo sito abbiano la possibilità di essere inserite nell’indice e poi, magari, posizionate nelle SERP.
É lo stesso Google a indicare fra le sue best practices l’importanza di strutturare i siti web in modo che i contenuti possano essere facilmente richiamati dai suoi bot (ad esempio, per quanto riguarda la struttura di un ecommerce).
Esistono svariate strutture di gestione della struttura di un sito web intesa da un punto di vista tecnico. Ne ha fornito un’ottima sintesi Christian, in un post per il blog di Studio Samo (lo trovi a questa URL: https://www.studiosamo.it/struttura-siti-web/), dove ha parlato delle principali architetture per siti web e del loro rapporto non soltanto con la SEO, ma anche con la cura della UX.
Da un punto di vista puramente SEO, indipendentemente dal tipo di architettura che preferisci utilizzare, presta sempre molta cura a creare delle tassonomie verticali e gestire la navigazione in profondità. Tra l’altro, Gary Illyes di Google ha recentemente ribadito che, nei casi di siti web piuttosto strutturati, la gerarchizzazione dei contenuti è preferibile per facilitare il crawler sia nella scoperta che nella pianificazione della scansione dei contenuti.
For a large site it’s likely better to have a hierarchical structure; that will allow you to do funky stuff on just one section, and will also allow search engines to potentially treat different sections differently, especially when it comes to crawling.
For example, having a /news/ section for newsy content and /archives/ for old content would allow search engines to crawl /news/ faster than the other directory. If you put everything in one directory, that’s hardly possible.
Fonte: Gary Illyes, dal Canale YouTube di Google Search Central
Se vuoi ascoltare l’intero Podcast lo trovi qui sotto. La domanda sulla struttura dei siti è post circa al minuto 1.35.
Gestione delle Breadcrumbs
Sai qual è il modo migliore per aiutare utente e motore di ricerca ad orientarsi nella struttura del tuo sito web? Impostare correttamente le Breadcrumbs.
Le Breadcrumbs (o “briciole di pane“) sono una tecnica di navigazione ampiamente diffusa sui siti web, che rappresentano visivamente il percorso in profondità all’interno della struttura del sito. Sono (o dovrebbero essere) poste in ciascuna pagina, segnalando il punto esatto dove ci si trova e il percorso da fare per arrivare dove si è.
Un po’ come il “tu sei qui” che trovi all’interno di centri commerciali, parchi, ospedali o strutture molto grandi, con tante diramazioni.
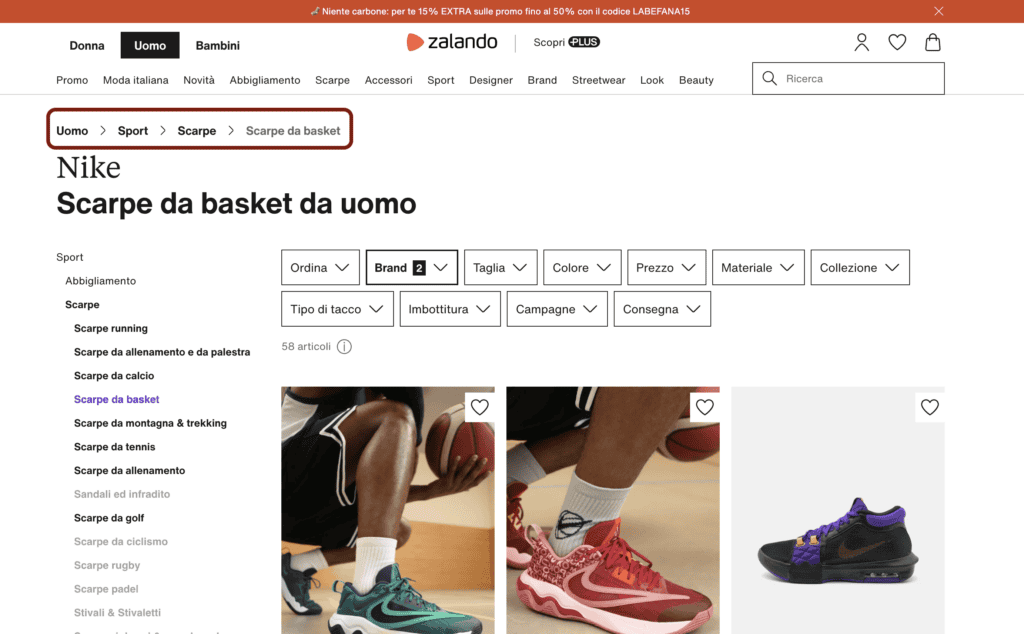
Nell’immagine, puoi notare come il celebre ecommerce Zalando gestisce le sue Breadcrumbs (cerchiate in porpora). Sono nella pagina “scarpe da basket”, che appartiene alla pagina “scarpe”, che appartiene alla pagina “sport”, che appartiene alla pagina “uomo”.
Il percorso che porta dalla categoria generale “uomo” alla categoria specifica “scarpe da basket nike” è tutto racchiuso lì, insieme all’architettura del sito.
Ricordati sempre di renderle disponibili per gli utenti e per i crawler (che le utilizzano appunto per trovare nuovi link da scansionare e per comprendere meglio la struttura del tuo sito). E, soprattutto, ricordati di impostare i dati strutturati BreadcrumbList per rendere ancora più evidente il tutto (se non sai di cosa sto parlando tranquillo, lo accennerò più avanti in questo articolo!).
Permalink
Sui permalink non c’è molto da dire, in realtà ma, trattandosi di un’operazione massiva da effettuare prima di pubblicare bilioni di contenuti, ne parliamo in questa fase e via.
L’URL delle pagine in sé non è un forte segnale di ranking (anzi, probabilmente non lo è per nulla). Quello che però deve esserti chiaro è che l’URL dovrebbe essere search engine friendly. Ovvero, non dovrebbe riportare numeri, prefissi o suffissi comprensibili solo dal tuo CMS. Piuttosto, dovrebbe parlare. Se stai creando la pagina delle scarpe da basket Nike, chiamala /scarpe-da-basket-nike/, non /index.php?page=143.
É un piccolo tassello, ma al solito meglio averlo che non averlo.
Canonical
Il tag Canonical, o rel canonical o semplicemente canonical, è un tag html che indica qual contenuto è prioritario fra due o più di due.
Se implementato correttamente, è un tag particolarmente importante per prevenire duplicazioni di contenuto (tanto interne quanto esterne al tuo sito) e correggere o cercare di evitare cannibalizzazioni a livello di query nelle pagine, soprattutto quando la differenza di contenuto è davvero minima.
Di fatto, inserendo il tag Canonical in una pagina si suggerisce al crawler una preferenza verso un altro contenuto del sito (o esterno al sito: in questo caso si parla di external canonical).
Se ti riesce difficile pensare al perché dovresti usare il canonical per “sfavorire” un tuo contenuto rispetto a un altro, pensa a tutti quei casi in cui sei costretto a creare due pagine molto simili.
Un esempio? Le pagine dinamiche!
Gestione delle pagine dinamiche
Detta in termini spicci, le pagine dinamiche sono quelle pagine che “non esistono”, ma vengono create a seguito di un azione su un sito web. Sono generalmente identificabili da un parametro posto nell’URL, come ad esempio quello che trovi nell’immagine sottostante, sempre presa da Zalando.
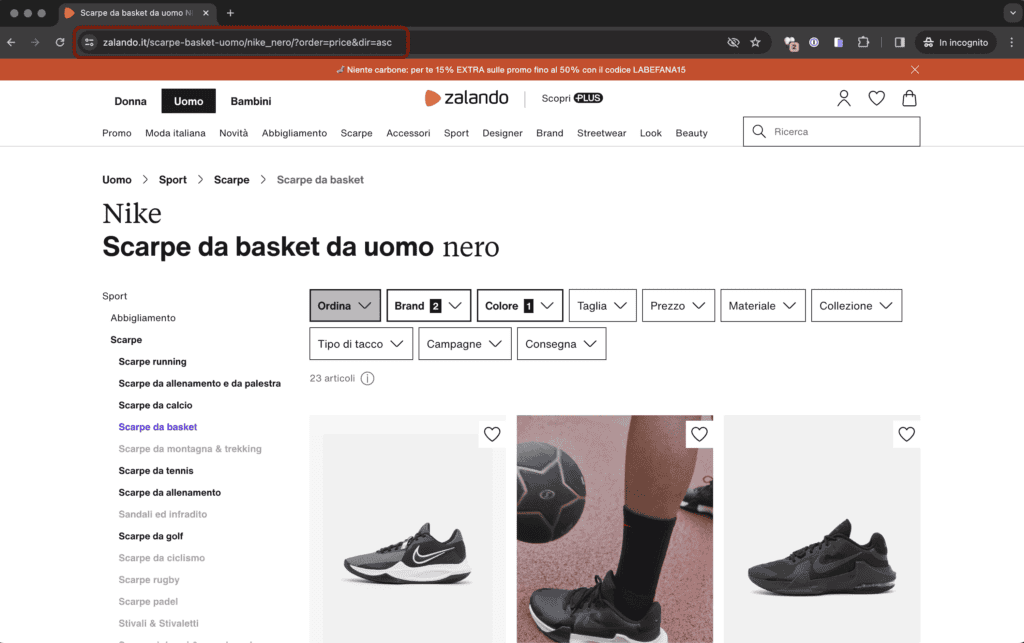
In questo caso specifico, come vedi c’è un “?order=price&dir=asc” attaccato alla URL di pagina. Quello significa che io ho chiesto al sito di mostrarmi i prodotti presenti nella categoria di scarpe da basket della Nike in ordine di prezzo ascendente.
La pagina, però, è sempre la stessa! Quello che è cambiato è la disposizione degli elementi al suo interno per la mia richiesta.
Un URL con parametri, come quella dell’esempio, è una URL differente rispetto alla stessa URL senza parametri. Ciò significa che, se non gestita, molto probabilmente sarà un duplicato. Il Canonical di cui abbiamo parlato nel paragrafo precedente è una delle possibili soluzioni per gestire questo tipo di contenuti.
Altro esempio potrebbe essere il motore di ricerca interno al tuo sito. Se ne hai uno, prova a cercare qualcosa e vedi che tipologia di URL viene fuori.
Ricordati sempre di gestire, se ne hai, le URL dinamiche. Possono fare dei veri e propri danni.
Link interni
Meno famosi e molto meno ottimizzati dei loro cugini Backlink, i link interni hanno un ruolo importantissimo nella strutturazione dei siti web. D’altronde, se considera che il World Wide Web è una ragnatela di link, la mia asserzione precedente è piuttosto ovvia, non trovi?
I link interni ti aiutano a collegare e votare le pagine del tuo sito. Linkando un contenuto di fatto lo consigli, tanto agli utenti quanto ai crawler. E questo ha un impatto notevole, se la tua ragnatela di link interni è gestita correttamente. Ad esempio, dando maggiore rilevanza (e quindi più link, con anchor text ragionate) verso contenuti che per te sono più importanti.
Puoi aiutare il crawler a scovare nuove pagine (quindi favorendo l’indicizzazione dei contenuti e – talvolta – migliorandone addirittura il ranking) e l’utente ad apprezzare ancora di più la sua navigazione sul tuo sito. Ricordati che l’esperienza dell’utente è fondamentale. Un utente che naviga più contenuti e rimane più tempo, soddisfacendo il suo obiettivo di ricerca, è sicuramente un bel segnale di ranking per il tuo sito!

Un esempio di applicazione dei link interni è il collegamento che, dalle pagine micro del sito (sottocategorie di prodotto o prodotti) riporta alle pagine macro (categorie primarie e homepage), per riportare del PageRank nelle parti “alte” del sito e indicare al motore di ricerca (tramite anchor text) le pagine più generiche di un sito web.
Impostazione della Sitemap
La Sitemap XML è la mappa del tuo sito, creata e messa a disposizione dei crawler per poter reperire e ri-trovare facilmente i contenuti da scansionare.
Semplicemente creala, caricala nel file robots.txt (che, teoricamente, è la prima chiamata di un crawler quando scopre un nuovo dominio) e, se l’hai verificata, inseriscila anche nella Google Search Console.
Se hai un sito di dimensioni modeste, avrà un impatto piccolo piccolo, ma potrebbe velocizzare i processi di indicizzazione dei tuoi contenuti, oltre alla velocità con cui Google si accorgerà di eventuali modifiche ai contenuti stessi,
Se hai un sito di grande dimensioni (centinaia di migliaia di pagine, per intenderci), la Sitemap è fondamentale. Google e gli altri motori di ricerca potrebbero semplicemente non trovare tutte le tue pagine. Mi è successo con una grande GDO italiana: 60000 pagine indicizzate in 24h, soltanto per aver generato la Sitemap XML del sito e averla caricata in Search Console e nel file Robots.txt.
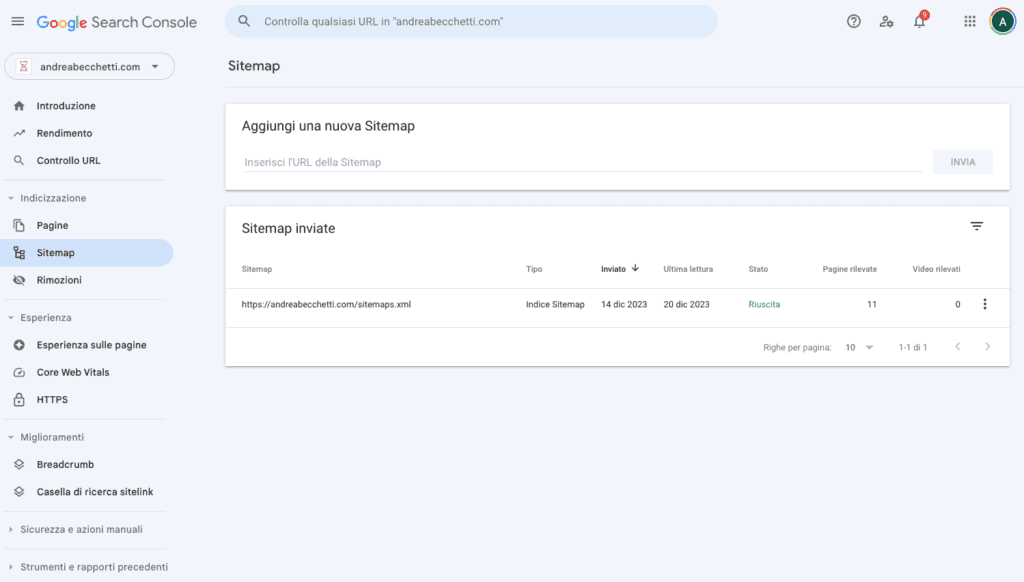
Se hai un sito voluminoso, ricorda l’unica cosa importante: c’è un limite di dimensioni o voci, oltre cui Google ignorerà l’intera Sitemap. Ogni Sitemap non può contenere più di 50000 voci e non può pesare più di 50MB (trovi la fonte dell’informazione fra le Best Pratices di Google). Se hai tantissime voci, valuta di spezzare la Sitemap in tante mappe, magari dividendole per “categorie”, “prodotti/post” e via dicendo.
Noindex e nofollow
Non tutto deve necessariamente essere indicizzato e non tutti i link del tuo sito dovrebbero essere seguiti. Il tag Noindex e il tag Nofollow assolvono queste due funzioni: il Noindex previene la messa in indice delle pagine, il Nofollow invita il crawler a non seguire un link verso la sua pagina di destinazione, e non considerarlo come un voto.
Alcuni esempi di applicazione? Ad esempio, potresti impostare un Nofollow su link che rimandano a pagine irrilevanti (ai fini SEO) del tuo sito, come quelli che rimandano alla creazione delle pagine dinamiche. Se non le vuoi in indice, perché consigliare al motore di ricerca di seguire i link?
Oppure, per quanto riguarda il Noindex, potresti decidere di rimuovere dall’indice Google una pagina che non vuoi più venga visualizzata dagli utenti nelle pagine dei risultati di ricerca.
Disallow da file Robots.txt
L’istruzione Disallow è un’istruzione preventiva. Serve a comunicare ai motori di ricerca quali pagine non devono essere scansionate. Di norma, le pagine sottoposte a Disallow prima di andare online vengono ignorate dal motore di ricerca e non mostrate nella pagina dei risultati. Non c’è garanzia che una pagina messa in Disallow non venga scansionata, ovviamente, ma per i nuovi contenuti i crawler tendono a rispettare la direttiva.

Se hai grosse porzioni di sito che non vuoi vengano prese in considerazione da Google, valuta di metterle in disallow da file Robots.txt prima di metterle online. Un esempio è rappresentato dai già citati filtri degli e-commerce, ma più in generale le pagine dinamiche (quelle con il parametro “?” nella URL) che, tendenzialmente, non devono essere indicizzate per evitare duplicazioni massive.
Ricorda che, per quanto serva a prevenire la messa in indice di contenuti, il Disallow non li esclude dall’indice se vi sono già inseriti. Se vuoi togliere contenuti dall’indice del motore di ricerca, meglio rifarsi al tag Noindex o ad altre soluzioni.
Extra-tip: il file Robots.txt può aiutarti anche a limitare le visite di crawler che non vuoi sul tuo sito. Non c’è garanzia che i bot rispettino il tuo comando, ma tentar non nuoce. Ti basterà inserire il nome del crawler che vuoi escludere al Robots.txt con l’istruzione Disallow.

Quello sopra è un esempio di file Robots.txt pensato per escludere tutti i crawler. Questa, ad esempio, è un’ottima pratica da usare per i siti in costruzione, per evitare che i bot scansionino e indicizzino contenuti che non dovrebbero prendere in considerazione.
Gestione dei Tag
Per l’amor di Dio, non usare mai i tag come fossero parole chiave.

I Tag sono archivi, proprio come le categorie. Se proprio hai bisogno di usarli, creali per creare tassonomie orizzontali, con l’obiettivo di occupare spazi nelle SERP non tenuti in considerazioni dalle tassonomie verticali (la struttura principale del sito, che va in profondità partendo dal macro e scendendo fino al micro).
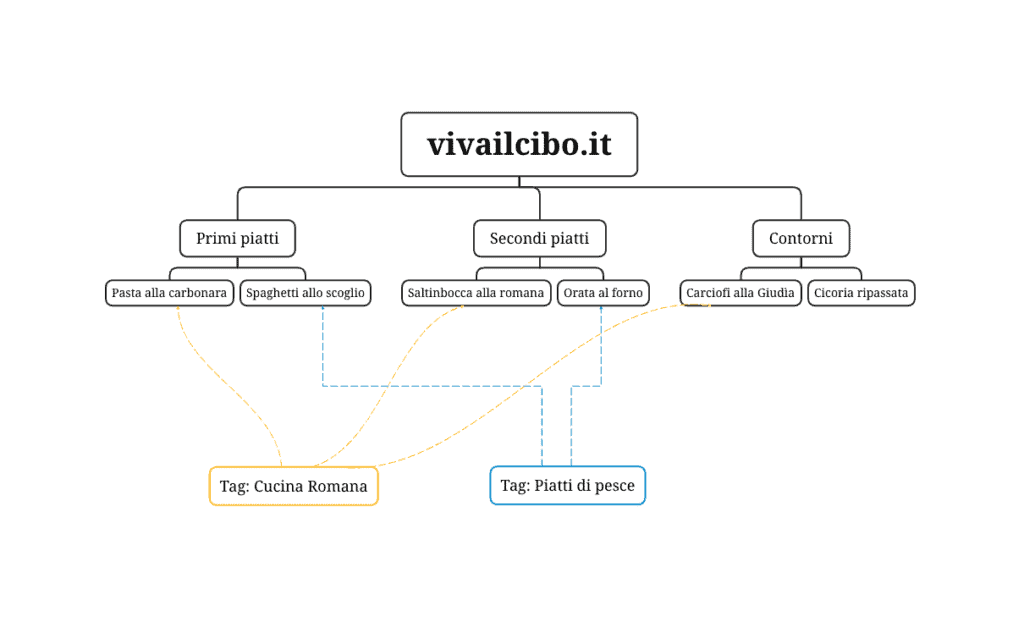
Ricorda che i Tag, in quanto Archivi, devono essere soggetti a ottimizzazione SEO On Page come tutte le pagine che hanno un obiettivo di posizionamento.
Evita nel modo più assoluto le liste di Tag (o Tag cloud) formate dalla ripetizione ossessivo-compulsiva di parole chiave scritte con variazioni o sinonimi. Non servono e anzi sono nocive, perché non fanno altro che creare duplicazioni e cannibalizzazioni.
Dati strutturati
Se non hai mai visto Schema.org è il momento di fare conoscenza.
Non è questa la sede corretta per una dissertazione approfondita, ma sappi che i dati strutturati sono le fondamenta dei motori di ricerca di oggi e, per quanto è dato a sapere, anche e soprattutto di domani. Accertati che il tuo sito presenti dati strutturati in html o JSON che aiutino i motori di ricerca a comprenderne correttamente e inequivocabilmente i contenuti.
Di solito, i CMS più utilizzati (WordPress, Prestahop e Magento, ad esempio) li incorporano di Default, e altrettanto fanno molti template fatti bene. Se vuoi fare una verifica veloce, puoi inserire il tuo sito su:
- validator.schema.org, dove potrai verificare se è presente uno o più dati strutturati fra tutti quelli esistenti;
- https://search.google.com/test/rich-results, dove potrai verificare se è presente uno o più dati strutturati fra quelli supportati da Google.
Ottimizzazione dei Core Web Vitals (e delle Performance in generale)
Dici che è inutile stare a ribadire che le performance sono una questione molto importante quando si parla di SEO? Secondo me no.
Di siti che impiegano ere geologiche a caricare le pagine, o la cui usabilità è fortemente pregiudicata dall’apertura di trilioni di banner e popup, il web è pieno. Le performance dei siti web, in particolare i Core Web Vitals, sono un segnale di ranking tenuto in considerazione dai motori di ricerca per valutare se i tuoi contenuti meritano di posizionarsi nelle loro pagine dei risultati.
Verifica ciclicamente che le pagine del tuo sito rispettino i requisiti minimi previsti dai principali motori di ricerca. Nel caso di Google, le informazioni sui Core Web Vitals sono disponibili sul post dedicato nel Google Search Central: https://developers.google.com/search/docs/appearance/core-web-vitals?hl=it.
Tiriamo le somme?
Ce n’è di roba da prendere in considerazione prima di dedicarsi alla stesura dei contenuti, non trovi? E queste sono soltanto alcune delle operazioni principali da fare, prese a riferimento considerando un “modello x” di sito web, generico e più o meno universalmente applicabile.
Ogni categoria di sito, anzi ogni sito in generale ha dei punti su cui concentrare l’attenzione. Puoi però usare la lista di operazioni precedenti come una cartina tornasole da guardare quando fai controlli globali su un sito, ad esempio durante un Audit.
Ti viene in mente altro, pensi che ho dimenticato qualcosa o non sei d’accordo su uno o più punti? Beh, i commenti esistono per questo!



